Rebuilding Premier Agent CRM from the Inside Out

On a sunny San Francisco morning, when the air was cool and crisp, and the sun rays like a prism, broke through the new shiny glass buildings filled with the latest and greatest tech companies. I walked across the street from under the elevated Salesforce Park, and under the cantilevered patio outside of Zillow's San Francisco office.
I was about to meet with a former colleague, Nico Raffo, to grab lunch. I was in the market for a new job, and Nico offered to help. As I walked up to the doors to the lobby of 535 Mission Street, I was greeted by another colleague, Tim Correia. Tim was the VP of Engineering & Product for Agent Platform at Zillow Group.
Tim Correia
About Tim. He is incredibly smart, kind, and a great leader. Sure, Tim was a level-headed and pragmatic leader, but he also cared about us. An example of this was when I bought a "fixer upper" home in San Francisco back in 2015, and Tim offered to let me borrow his old pickup Truck.

Tim let us keep that truck for four months! It was a serious life-saver... we didn't own a car at the time. We hauled away the old carpets, floors, some walls, cabinets, bathroom, and so much more.

So, needless to say, Tim had a special place in my heart, and I respect him immensely.
Rebuilding Premier Agent CRM
Tim and I chatted for a bit, and then he asked me if I was interested in coming back to Zillow. I told him I was. He had something specific in mind: which is my favorite way to work. He wanted me to come back to Zillow to help rebuild the Premier Agent CRM with newer technologies, and to use best practices. He also emphasized that he wanted to bring a number of engineers up to speed on the best practices of systems and code quality. I was sold. I'd just spent the last year and a half teaching myself React and Redux, as well as leading a small team at Earnest, so I was ready.
The Considerations
The Premier Agent CRM was initially created as a prototype, to show what could be done. It grew over the years into a fully fledged Lead Inbox, with deep contextual information about each lead embedded in deep nested components. When I spoke to engineers about the codebase, I heard a consistent and loud message:
- The codebase was complex and hard to understand
- Every change seemed to cause unintended side effects
- The technologies were outdated and not exciting for engineers to work on
- The codebase was not well tested
- The codebase was not well documented
- The codebase was not well architected
- The codebase relied on a homegrown framework which combined Marionette and Backbone, and some custom framework code that only one engineer understood.
I wrote down notes as I spoke with each engineer. I dove into the codebase, and tried my own hand at making modifications. I noticed that there was no single pattern for shipping code. Each engineer used their own intuition and style to get things done. Some engineers added onto existing components, while others created new components. The codebase was deeply nested, and references often traversed up and down the component tree. It was hard to tell where a component might be used. The component references were not statically linked, requiring a text search to find dependencies. All of this made it so difficult to make changes, that even the most Senior engineers (I'm thinking of you Kim) refused to take on tickets to make changes to the codebase.
The Approach
I knew that I needed to take a different approach to this project. I needed to get buy-in from the engineers, and from leadership. I gathered a long list of all the problems with the codebase. I organized the issues into themes.
- Technology: Outdated or non-standard technologies
- Architecture: Lack of cohesion or consistent patterns
- Testing: Inconsistent or non-existing testing standards
- Ease of Use: Difficult to understand how and where to implement changes and new features
- Documentation: Lack of documentation for the codebase, and how to use it
I then reached out to an engineer that I respect immensely, Jason Gruhl. I showed him my list of issues, and asked him to reflect with me on some potential approaches to getting buy-in on a rebuild. Even though we had buy-in at a very high level: Tim; We knew there would be resistance from other engineers if we just built another system with the same issues. Jason and I came up with a plan:
- Use modern technologies, which would:
- Be exciting and motivating for Engineers to work with
- Be easier to find engineers to work on the project
- Be easier to find engineers to maintain the project
- Use a simple and consistent pattern for building components
- Organize the components as flat as possible, to prevent deep nesting
- Use a consistent pattern for passing data and callbacks to components
- Minimize Ambiguity by publishing Code Generators that scaffold out components
Monumental Scope
Another issue, one which only a few leaders were aware of, was the monumental scope of the project. The Premier Agent CRM was a massive application, with hundreds of thousands of lines of code. It was used by thousands of Realtors, and was a critical part of their business. It was also a critical part of Zillow's business. We could not afford to take the application down for any period of time, and we could not afford to hold on feature development until the project was complete. We needed to find a way to rebuild the application, while continuing to develop new features and fix bugs. This was a monumental task, and one that I was excited to take on.
iFrames and Window:postMessage
My manager at the time was named Val Jordan, and his manager was Dave. Dave, Val, and I discussed strategies for dealing with the large scope. We discussed ways to replace one component at a time. How can we slice the application into smaller pieces, and replace each piece from the inside out. It was tricky, because the Backbone and Marionette code was a tangle of complexity. We realized that if we started with the UI, we could simply replace the rendered UI within any given element, and leave the underlying code in place. This was brilliant, because it meant that we could build new components completely in React, and then simply replace the rendered HTML within the existing application.
We devised a way to use iFrames, and inter-frame Window:postMessage communications to pass state changes between
the old application and the new application. This allowed us to build new components in React, and then simply send
the minimum information needed to update the React UI from the old application. We built a prototype to prove it
could be done, and found that not only could it be done, but the result was indistinguishable from the old UI.
The iframe would replace a specific component, using some clever CSS tricks to hide the old component and show the
new React Application. Inside the iframe, we would render the new React application. We would pass any state changes
to the React application via Window:postMessage. The React application would then make the necessary updates
to its UI. This approach meant we could leave the old application completely intact, and simply replace the UI one
piece at a time. If we ever needed to bail, or if we ever needed to roll back, we could simply remove the iframe(s).)
The Plan
The plan from that point on was to dedicate myself and two other engineers to go heads down on replacing each component one at a time, and shipping continuously. We would build a new component in React, and then replace the old one. Over the course of the project, the old application would incrementally become the new application. This would allow us to gather feedback as we progressed, and to make adjustments as needed.
The Method: Consistency Through Documentation as Code: Code Generators
We developed an organizing set of principles for the new application. The new application would be clean code. Every component would follow a consistent pattern, in terms of the style, placement, naming of files, and the way it was tested. We created some Code Generators using Yeoman, which would scaffold out new components.
You can check out a version of these generators is open sourced here: https://github.com/bpanahij/react-generator
The generators could create:
- React Components
- Redux Actions
The generators would create the files, and then insert the necessary code into the files. The generators would also wire everything up, so that immediately you could include your component and see it rendered in the application, with access to the Redux store.
We made sure to follow the best practices at the time for React and Redux: functional components, and an immutable store, as well as a flat component directory structure. To ensure this was maintained, We added in a tool: immutable. js to prevent state from being directly mutated. In Redux, avoiding direct mutation of state was vital to preventing aberrant bugs.
The Rules: Every Change to Architecture Must Have Generator Code
We made a rule that every change to the architecture must have a corresponding generator. This ensured that as the architecture matured and evolved, the generators would evolve with it. This enabled our team to continue to move fast while maintaining a consistent architecture. Old components could be updated by simply running the generator, and taking the business logic from the old code and moving it into the new component.
This had another side effect: when engineers sought to change the structure and patterns of the codebase, they would need to think about how other engineers would use their changes. They would need to think about how to update the existing codebase, and also whether their changes fit more use cases that their immediate needs. This helped to ensure that even if were not solving for all future use cases, we were at least thinking about the impact of our changes on the future.
Development and Delivery: Continuous Delivery
We established a CI/CD pipeline using Jenkins, which automatically built each Pull Request (PR) and deployed it to a dedicated environment for review by the product and QA teams. We employed Docker containers to ensure a consistent development and testing environment, aligning local development with PR, staging, and production setups.
However, this approach proved to be somewhat resource-intensive. After completing the CRM Refactor, we began collaborating with the infrastructure team on a new infrastructure-as-code implementation using Terraform. There was some overlap between the initial Terraform templates and our Docker-based CI/CD pipeline, leading to redundancy.
Initially, we maintained both approaches, but eventually, we integrated Terraform templates into our process to eliminate duplication. These templates were shared across the entire organization.
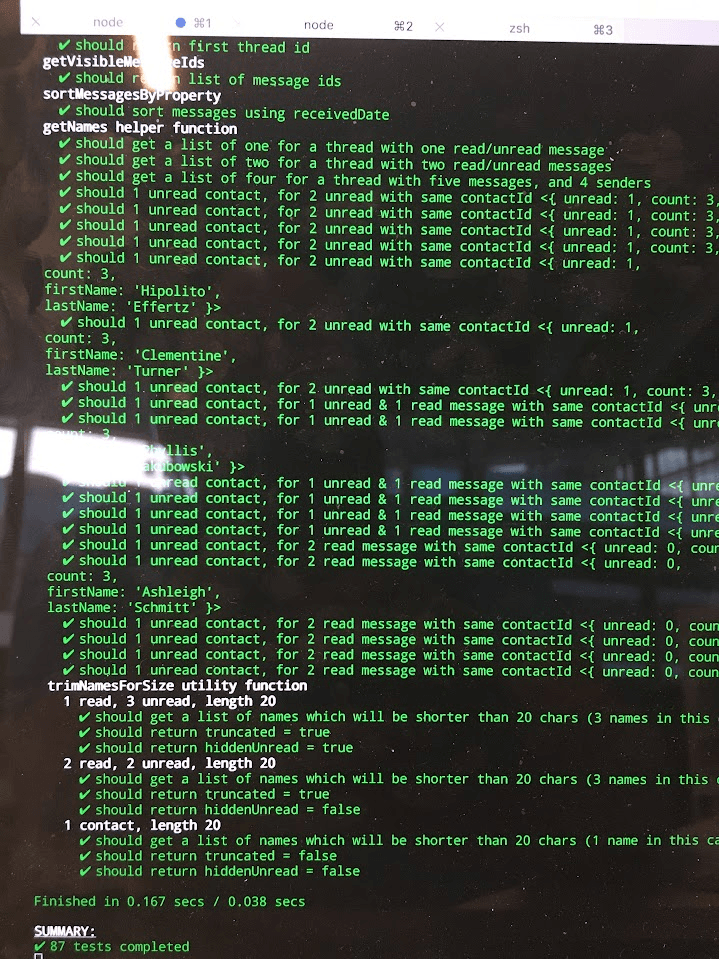
We incorporated a new testing suite into our PR (Pull Request) pipeline, making it mandatory for all PRs to pass a set of Unit and Smoke tests before merging. This ensured the codebase consistently passed tests, providing a safe path for deploying changes to production. Initially, our goal was to achieve 100% code coverage, excluding boilerplate code, which we almost accomplished. However, this approach had its drawbacks, which I'll explain later.
Nevertheless, our emphasis on achieving high code coverage had a positive outcome - it ensured that our most critical code was thoroughly tested. We assessed various metrics, including branch coverage, line coverage, function coverage, as well as the number of tests and assertions. These efforts received accolades from our QA team, a significant achievement for our organization. This success was particularly beneficial because we had limited QA resources, allowing more time for manual testing of our mobile application, which was challenging to automate.
The Results
The result of all this planning and execution on how we write code, and how we deploy it, led to a very stable and easy to use codebase. We were able to ship new features and bug fixes at a rapid pace. We were able to onboard new engineer rapidly. We had the opportunity to create a new team responsible for implementing the backlog of features that had built up on the old application. We also had the opportunity to work with product to dream up new product ideas. Over the next four years, my team grew to nine engineers, and owned nearly the entire Premier Agent CRM user experience, as well as the APIs, and integrations to the rest of the Zillow Group ecosystem. My role evolved from technical lead to engineering manager, and I was able to hire and mentor a number of engineers.

Eventually, my team grew too large, and we split into two teams. One team focused on the Premier Agent CRM Inbox, and the other the Premier Agent CRM Contact Experience. I was the engineering manager for the Premier Agent CRM Contact Experience. We were responsible for the Contact Experience, which included the Contact Record, Contact Details, and several integrations across Zillow Group to bring contextual information about the contact into the Contact Record.
The Mistakes
We made a number of mistakes along the way. I'll list them here, and then explain how we fixed them.
- We aimed for 100% code coverage
- We did not have a dedicated QA team
- We underestimated the time and complexity of the project
- We too strictly enforced the flat component structure
- We split the team into two teams, without a clear separation of responsibilities
100% Code Coverage
When we aimed for 100% code coverage, we believed that having a lofty goal would help us to achieve a high level of testing. We were right, we did achieve 95% code coverage. However, this created a lot of unnecessary tests, and some of those tests became flaky, unreliable, and difficult to maintain. We also found that we were writing tests for the sake of testing, rather than with a specific purpose, rule, or goal in mind. We were writing tests to achieve 100%. Eventually, we realized that we needed to remove the tests that were not providing value, and that we needed to have better rules for when to write tests.
We decided to only write tests for business logic, and to not write tests for trivial or boilerplate code. We also decided to not write UI Unit test, and instead rely on end-to-end tests for the user experience. This was a tradeoff I was unconvinced about initially, because I felt that Unit Test would be more reliable and faster to run. However, with the rapidly evolving UI, we found that the UI Unit Tests became too specific, and without the context of the entire application, they were not useful. Also, we rarely had bugs in the UI, because most bugs were caused by business logic, and the UI was simply a reflection of the business logic. Finally, with the UI Functional Tests, the Unit Tests were redundant in many cases.
No Dedicated QA Team
Initially, leadership on PA was so impressed with our ability to ship new features and bug fixes, and the high quality and level of test coverage, that they gave us the option to remove the QA team from our process. The QA team was onboard because they rarely found bugs in our code, due to the PR level functional testing and the high level of Unit Test coverage. However, when we realized our mistake on code coverage, we also realized that we needed a QA.
Underestimated Time and Complexity
Our initial estimate for replacing the Premier Agent CRM was 6 months. We were wrong. It took us 9 months. We failed to take into account the full complexity of several deeply nested features, and had not prenegotiated with product the tradeoffs we would make to simplify those features, or whether to at all. We also failed to take into account the cost of maintaining two codebases during the transition. When a bug arose in the old system, it would sometimes be difficult to know whether to fix it in the old system, or the new system, or both. Some bugs are actually the result of underlying business logic, or APIs.
Too Strictly Enforced Flat Component Structure
We enforced a flat component structure, which meant that we could not nest components. This was a mistake, because eventually the PA CRM grew so large, that the list of components was too long. One specific issue with that was the mixture of complex and simple components in a single list. It became difficult to find the component you were looking for and naming collisions were possible, and a constant conscious effort to avoid. We eventually relaxed the rule, and allowed for nested components, but with a strict rule that the nested components must be used only within the parent component.
Split the Team into Two Teams
We split the team into two teams, without a clear separation of responsibilities. This was a mistake, because it led to overlaps in responsibility. The Inbox team showed contact information inline in the Inbox. Some of the display logic was complex, and required our deeper knowledge and resources to implement. Even bigger a mistake was splitting the codebase. We used some of the same logic from the rebuild to justify splitting the codebase to free up developers to move forward on new features without being blocked by delays between teams, coordination, or CI/CI pipeline failures. The issues we tried to avoid could have just been addressed directly by fixing the CI/CD pipeline. Splitting the codebase led to a number of issues, including:
- Duplication of code
- Duplication of effort
- Introduction of bugs around maintaining state between the applications
The Lessons
We learned a lot from this project. I'll list the lessons here in short:
- Use rules that mirror your business requirements when writing tests
- Keep a dedicated QA team to ensure objective quality
- Estimate the time and complexity of the project, and add a hefty margin. Some say double it.
- Relax rules that are not providing value
- Don't apply lessons from one problem to another problem without considering the differences
The Takeaways

Replacing the old CRM with the new CRM from the inside out worked well. We managed to ship features quickly, while improving the architecture of the underlying systems. We were able to maintain a high quality of code, and shipped very few bugs over the course of four years. We were able to hire and mentor a number of engineers, and we were able to grow the team and elevate many engineers to new levels in the process. The CRM worked well for the business, and unlocked a whole new set of features and integrations that were not possible before. The CRM was a critical part of every initiative at Zillow.